机器学习应用建议
When we test our hypothesis on a new sets of data samples, we find that it makes unacceptably large error in its predictions. We can try:
- Get more training examples
- Try smaller sets of features
- Try getting additional features
- Try adding polynomial features
- Try decreasing/increasing
But it’s hard to say a certain attempt will always work, so we have to try different types of improving.
Machine learning diagnostic
Diagnostic: A test that you can run to gain insight what is/isn’t working with a learning algorithm, and gain guidance as to how best to improve its performance.
Diagnostic can take time to implement, but doing so can be a very good use of your time.
Evaluate hypothesis
Split dataset
If we have a known dataset, we can separate it to two parts: 70% for training, 30% for testing. However, the selection method should be random. If the dataset is sequential, we should randomly shuffle or reorder it first, then we can pick the first 70% and last 30% for training and testing respectively.
We provide a subscript for test dataset:
misclassification error, 0/1 error
For logistic regression model, we can useerr(h, y) function to evaluate the error of hypothesis. Take 0.5 to be the threshold, when error, make err(h, y) = 1, then add them up.
Select model and cross validation
Suppose that there are ten models to choose among: From linear, quadratic, cubic to decimetric. And we want to pick one of them. In this case, we can use cross validation to help us select the model.
We divided the dataset into three parts: training, cross validation and test. eg 60%, 20%, 20% respectively
For hypothesis of each order, we find the best parameter by minimizing cost function. Then we calculate the error of each hypothesis on the cross validation set. And pick the best one. Finally, evaluate it on the test set.
bias and variance
Underfit: high bias. The degree of polynomial is too small. High training set error and high cross validation error also, and they are close.
Overfit: high variance. The degree of polynomial is too large. Low training set error but high cross validation error,
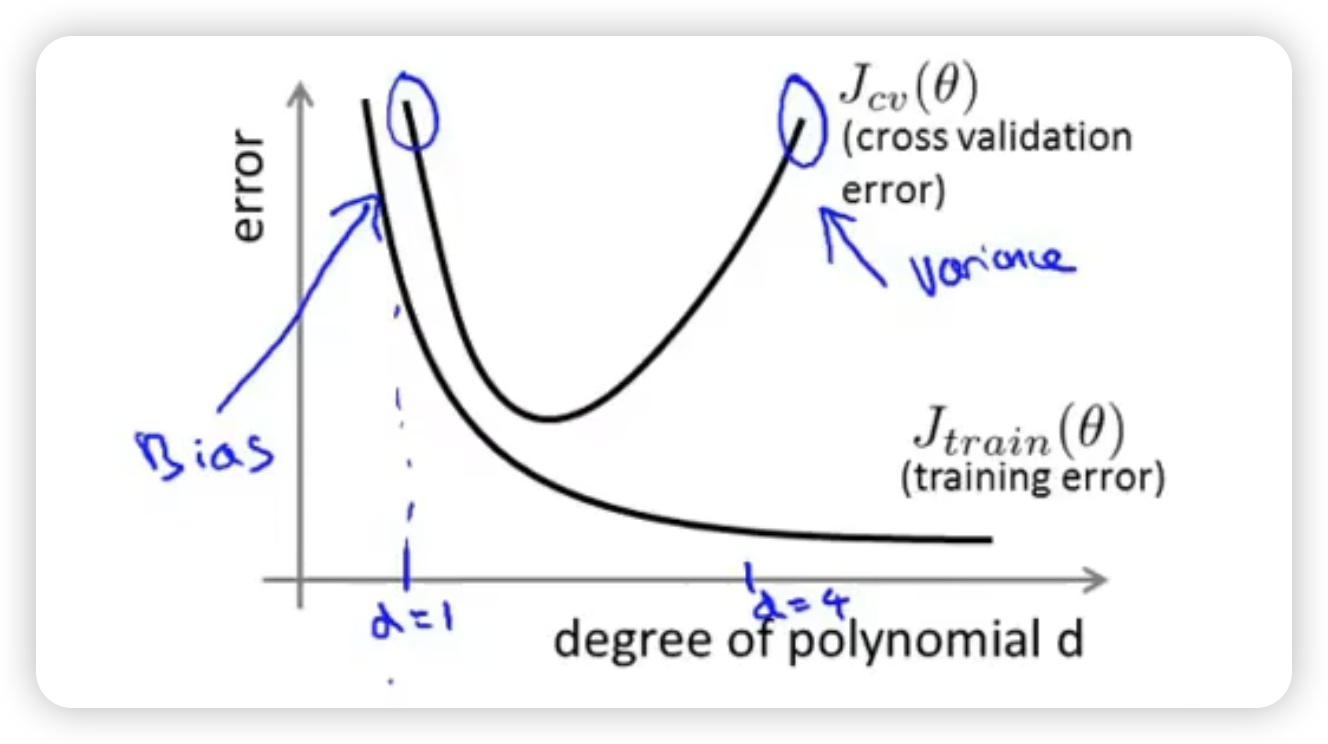
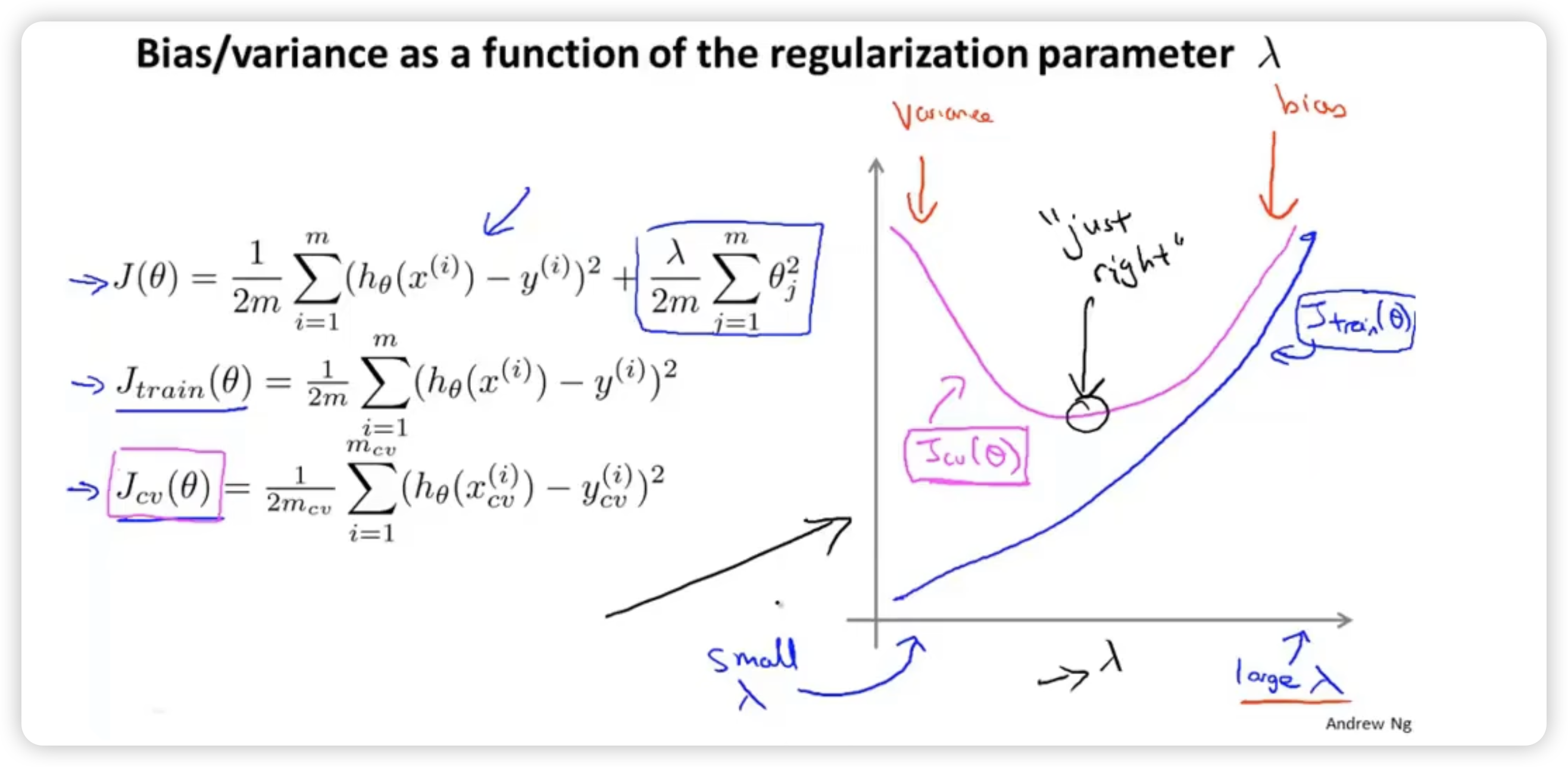
select regularization term
Like choosing the order of hypothesis, we can first use training set to minimize cost function of every hypothesis whose are different to get the parameter , and then calculate and choose the hypothesis with the smallest error.
learning curve
High bias
When high bias, for example, maybe because we choose a linear model. When the training set is small, we can get a linear line to fit it without big error. But this will lead to poor generalization, which means that is very big. When the training set is big, the linear model will be stable and change a little when increasing the size of training set. So will be smaller than that in the case of small training set. And finally, the two types of error will be close to each other.
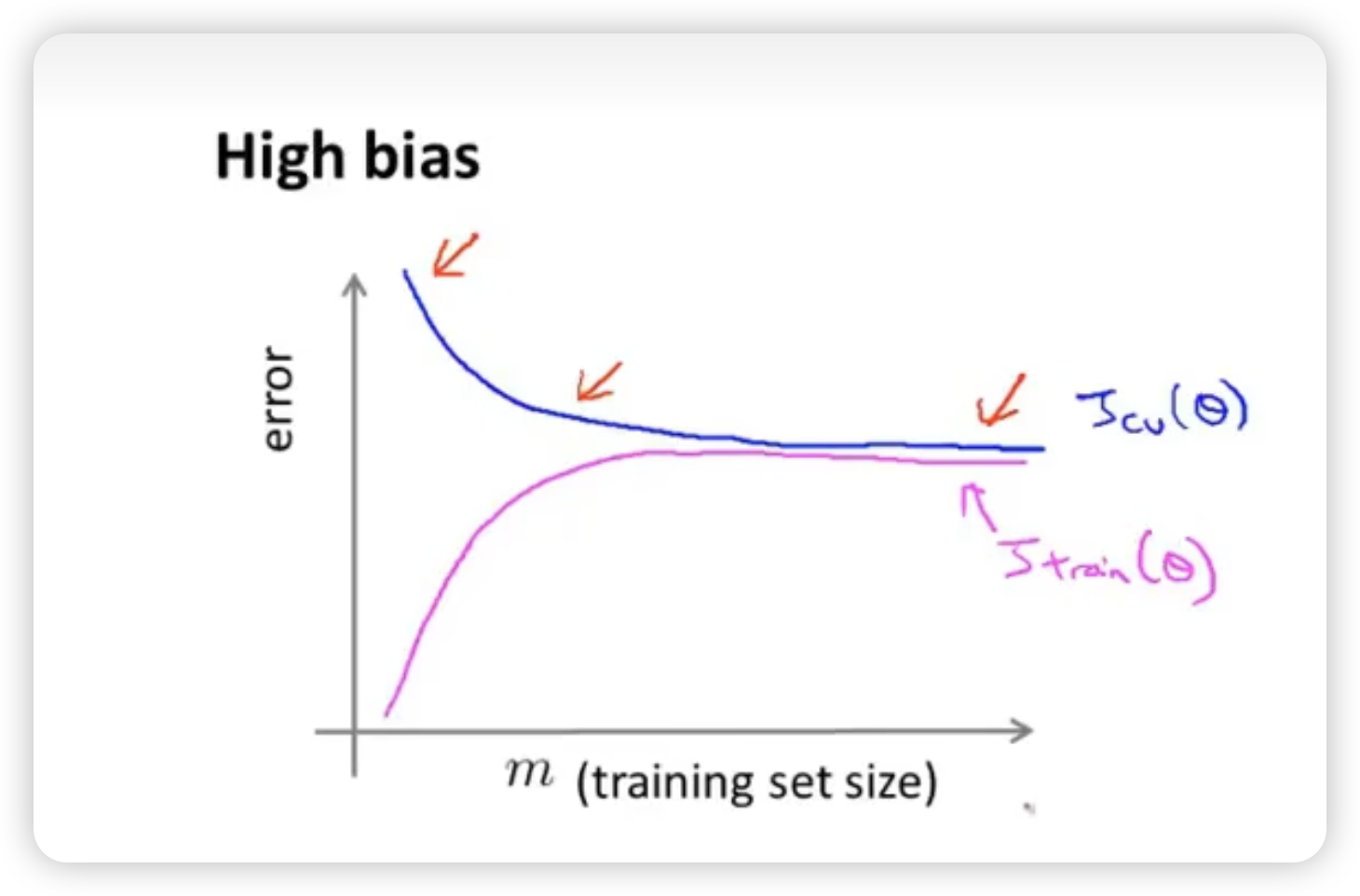
High bias case will end up with both high error of and when the training set size is big enough. Getting more training data will not help much.
high variance
The overfitting causes the poor generalization continually. And there is a large gap between two types of error.
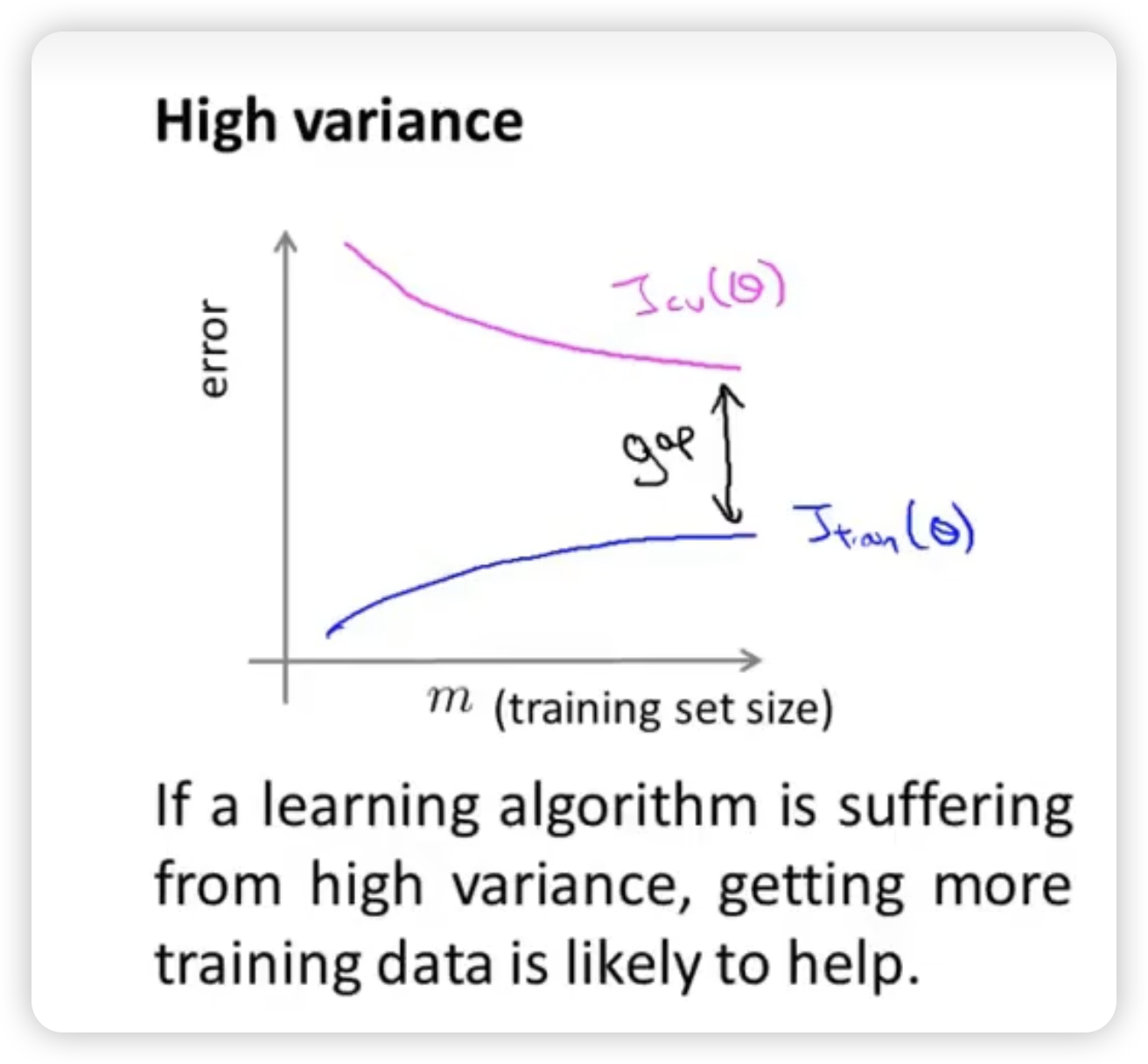
Enlarge training set is helpful in the case of high variance.
debugging a learning algorithm
- Get more training examples - fixes high variance
- Try smaller sets of features - fixes high variance
- Try getting additional features - fixes high bias
- Try adding polynomial features - fiex high bias
- Try decreasing - fixes high bias
- Try increasing - fixes high variance
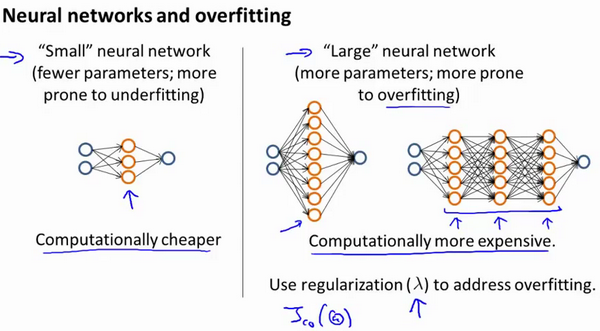
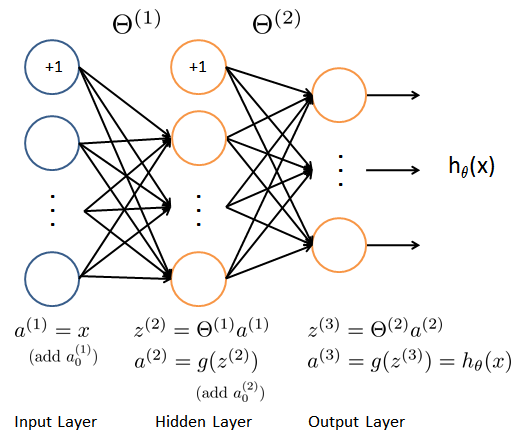
Small neural network: tend to underfit and bias
Large neural network: tend to overfit, but can be solved by regularizing
So we usually choose large neural network using regularization, which is better than small neural network.