机器学习笔记_基础
application examples of machine learning
- Database mining 数据挖掘
- 让计算机学习操作, 规划
- 手写识别
- 自然语言处理
- 计算机视觉
- 个性化推荐
Samuel 通过与计算机下棋, 让计算机学会了下棋. 并且比Samuel下得还好.
TEP理论
T: task 让计算机完成的任务内容. 给邮件分类, 是否垃圾邮件
E: experience 让计算机观察学习人类是如何给邮件分类的.
P: performance measure 性能测试. 看看计算机给邮件分类的效果如何, 正确率多少.
algorithms
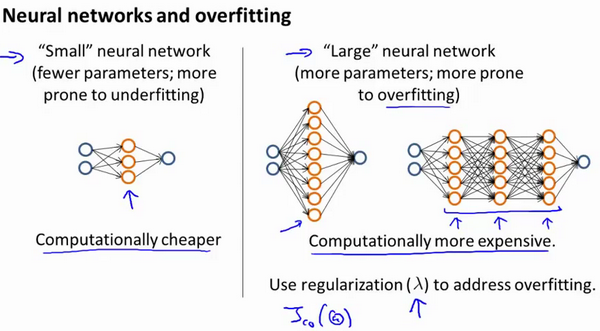
- supervised learning
- unsupervised learning
有监督学习: 教计算机干活.
例如我们想预测, 即让计算机拟合直线/二次曲线, 需要先给他一个数据集data set, 里面包含了正确答案. 计算机以此产生出更多的正确答案.
一种形式被称为regression回归问题. 得出的是拟合的线的表达式, 可以得出线上任意一点的值 real-valued
另一种是classsification 分类问题. 处理和得到的是discrete的数值, 即离散的. discrete-valued
无监督学习: 让计算机自己学习干活
聚类问题: 只给一些数据, 并不知道这些数据每个都应该被分到哪个类型. 即没有给出任何正确答案.
鸡尾酒会问题: 很多人说话, 听不清, 需要区分每个人的声音. 一种算法可以区分不同人的声音并做出分离.
总的来说都是给定数据, 不给出正确答案, 让其自己找到分类的方式和类型.
linear regression
线性回归. univariate: 单变量.
trainning set: 训练数据集. 例如在一元线性回归中, 给定几个已知的点. 这几个已知的点就是训练数据集
cost function
代价函数. 平方误差代价函数是解决线性回归问题的最常用手段.
让代价函数最小化, 以得到合适的参数, 用于描述线性方程.
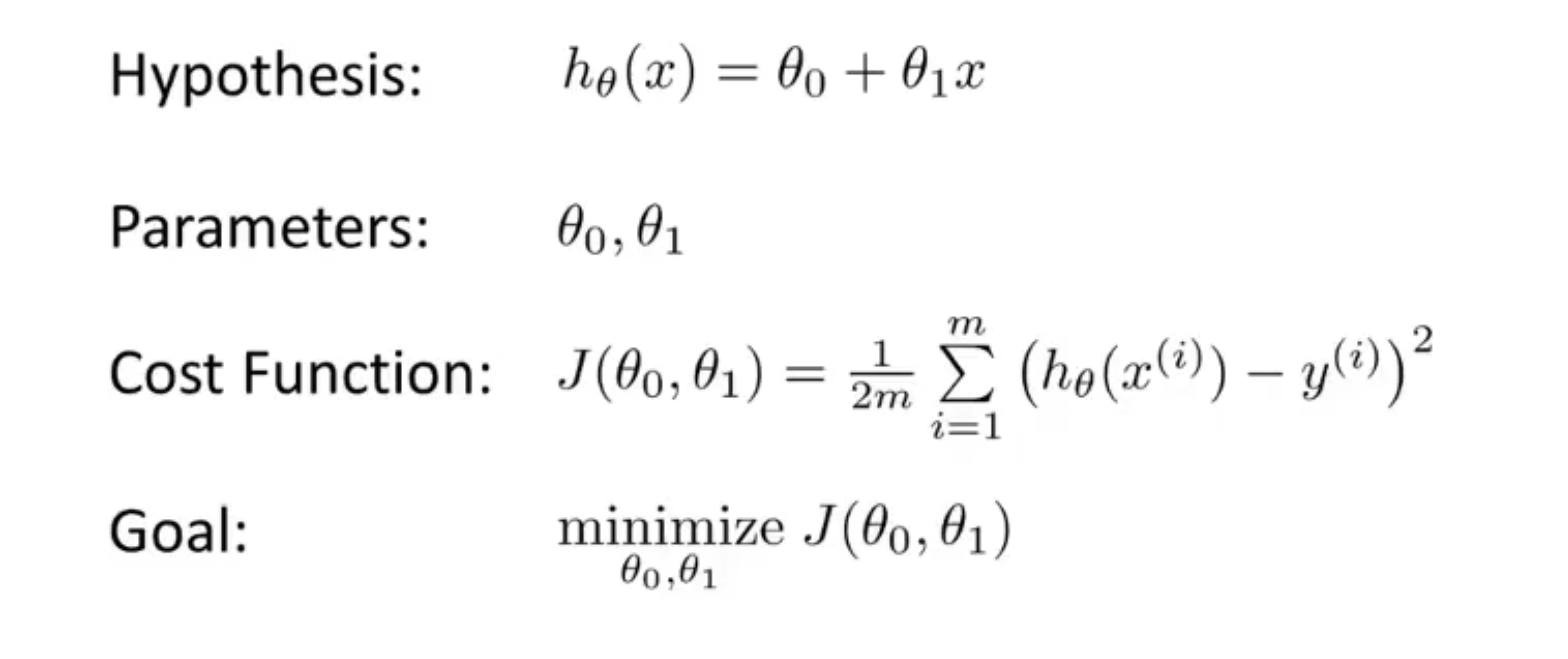
对于线性回归, 拥有两个变量k和b, 其代价函数的图像是三维的碗状的. bowl shaped曲面
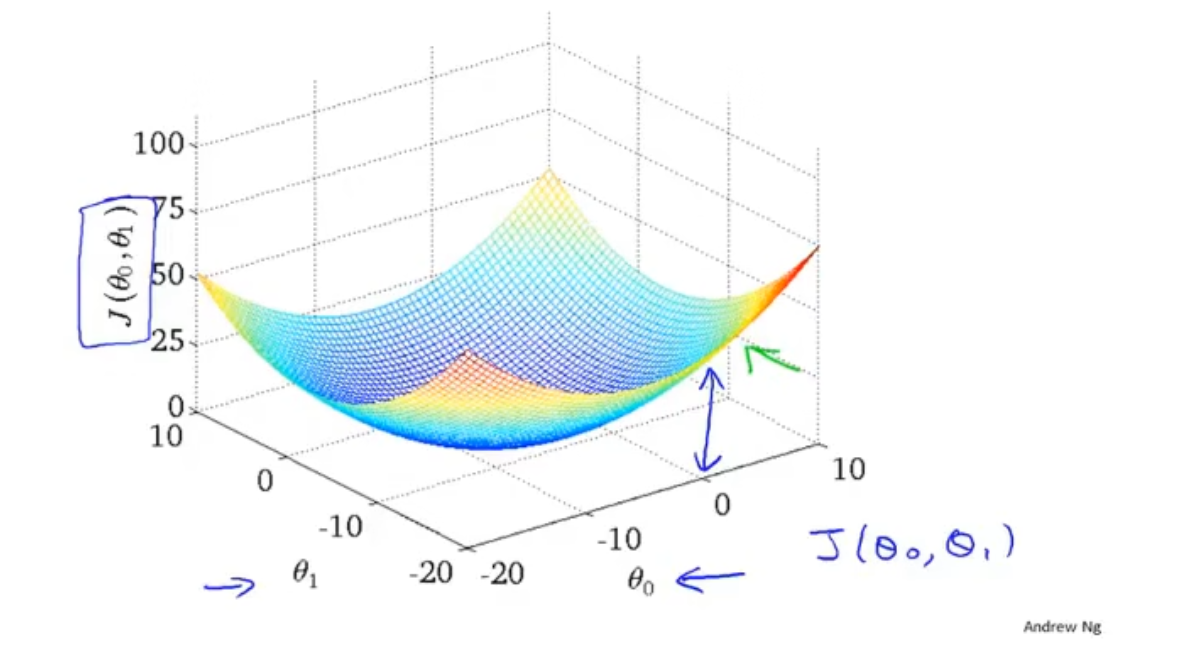
最低点即代价最小的点.
contour plot: 等高线图. 根据不同的J可以画出很多个同心的椭圆(这个说法应该不是严谨的只是表意). 同一个椭圆上的点表示代价函数相等.
gradient descent 梯度下降法
在曲面上的某个点开始, 找到下降最快的方向, 前进一小步; 在新的位置重复操作, 直到收敛到一个局部最小值.

assignment: 赋值 assertion: 声明
参数阿尔法被称为learning rate 学习速率. 决定了以多大的幅度更新参数. 学习率恒为正. 如果学习率太小, 则梯度下降法的速度会很慢; 如果学习率太大, 则容易跨过最低点. 但是步伐并不只由学习率决定, 还有导数决定. 当导数减小时, 越来越趋近正确的点, 步伐也会相应变小, 也就不必去减小学习率了.
当经过梯度下降法得到最低点时, 也就是局部最优点, local optimum 导数项(偏导)等于0, 所以参数theta将不改变.
注意: 为了确保两个参数同步更新, 需要用temp变量临时存储, 再统一进行更新, 不可异步迭代 (联想到高斯赛德尔迭代)
linear regression algorithm
结合梯度下降法. J是平方差代价函数 对于线性回归, 不会存在局部最优, 只有一个全局最优点.

这种梯度下降方法叫做 Batch梯度下降.
Batch: Each step of gradient descent uses all the training examples.
每一步都用到了所有的数据集.
下面是Gradient descent for linear regression的迭代式:
注意复合函数求导就行,没什么难度
以下是第一次作业
代价函数和梯度下降法的代码实现
基本的读取数据和作图
data = load('ex1data1.txt'); % 加载数据, 赋值给data矩阵 |
构造cost function代价函数
X = [ones(m, 1), data(:,1)]; % Add a column of ones to x |
梯度下降法进行迭代, 找到最佳的theta. 需要注意的点是必须进行同步迭代, 不能类似高斯赛德尔之类的异步迭代
% 其他人的答案 |
别人的答案选择通过循环每次修改一个theta的元素; 我的答案选择直接修改theta整个向量.
显然他的答案更加容易理解, 并且容易在第一次就写出来; 但是我的答案经过了多次修改, 在构思时会有一定的混淆, 不易直接写出.
后来我发现原因了, 因为我已经学到了向量化vectorized而这个作业是没学向量化的时候写的…
绘制图像
hold on; % 不清除已经存在的图形 |
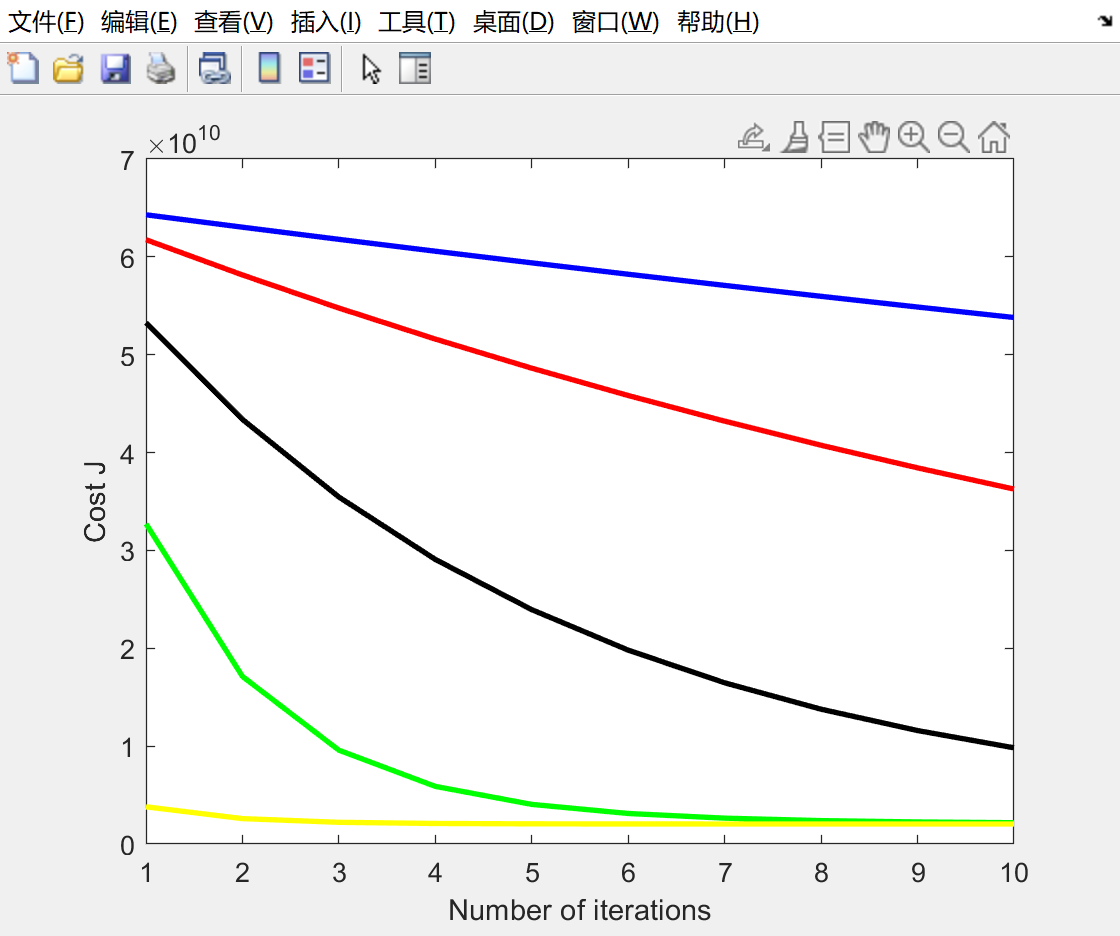
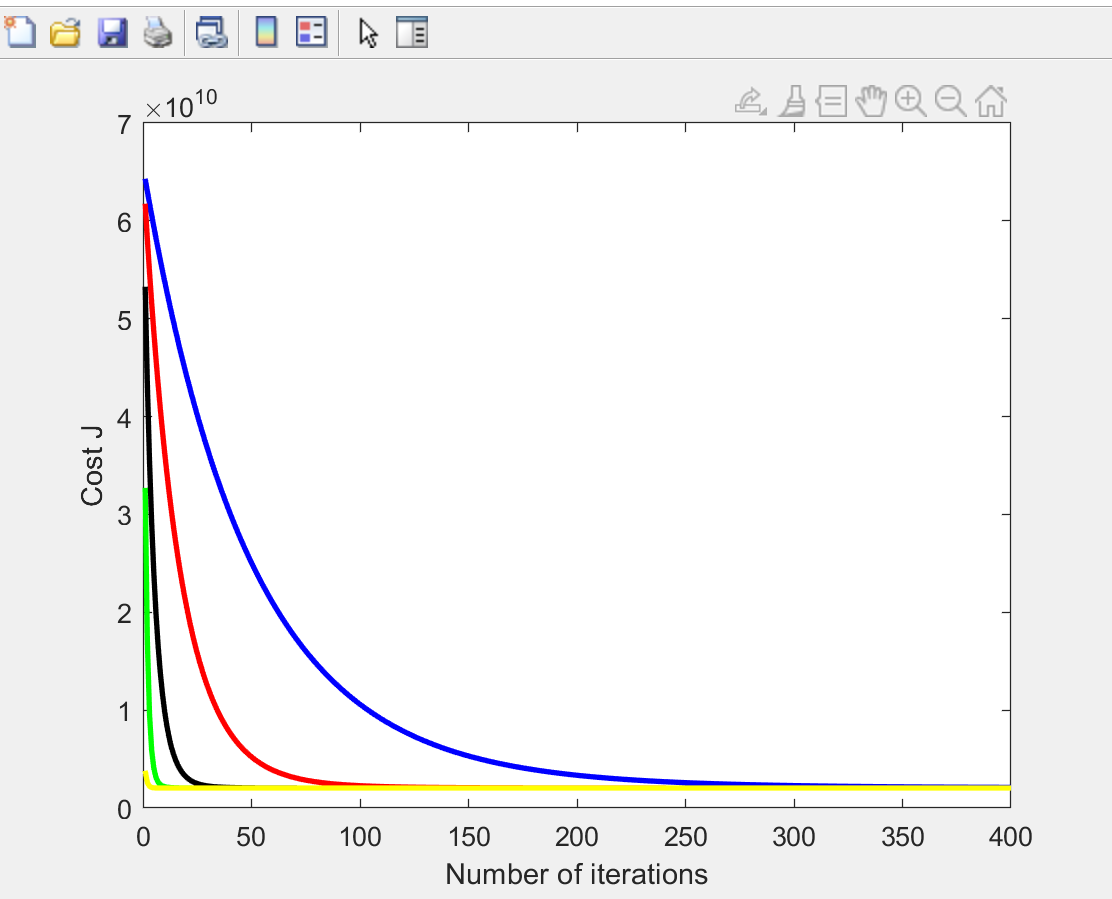
convergence 收敛性可视化
在梯度下降的过程中, 记录每次iteration迭代之后, 代价函数J的值到一个数组J_history中. 之后做出迭代次数(J_history数组下标)和J_history数组元素的函数图像
plot(1:numel(J_history), J_history, '-b', 'LineWidth', 2); |
当学习率改变时:
- 学习率增大, 收敛速度加快
- 学习率过大, 收敛转变为发散 diverge
五种不同的学习率:
但当学习率进一步增大:
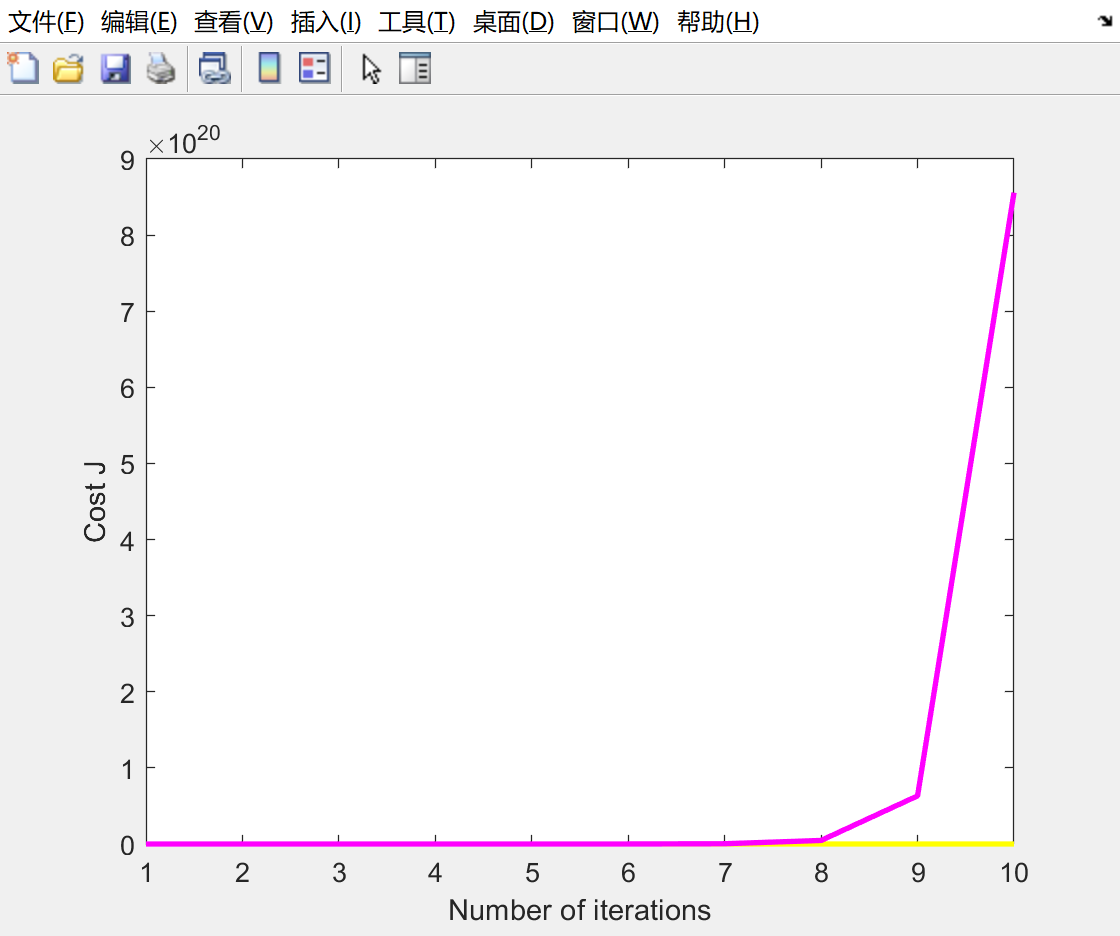
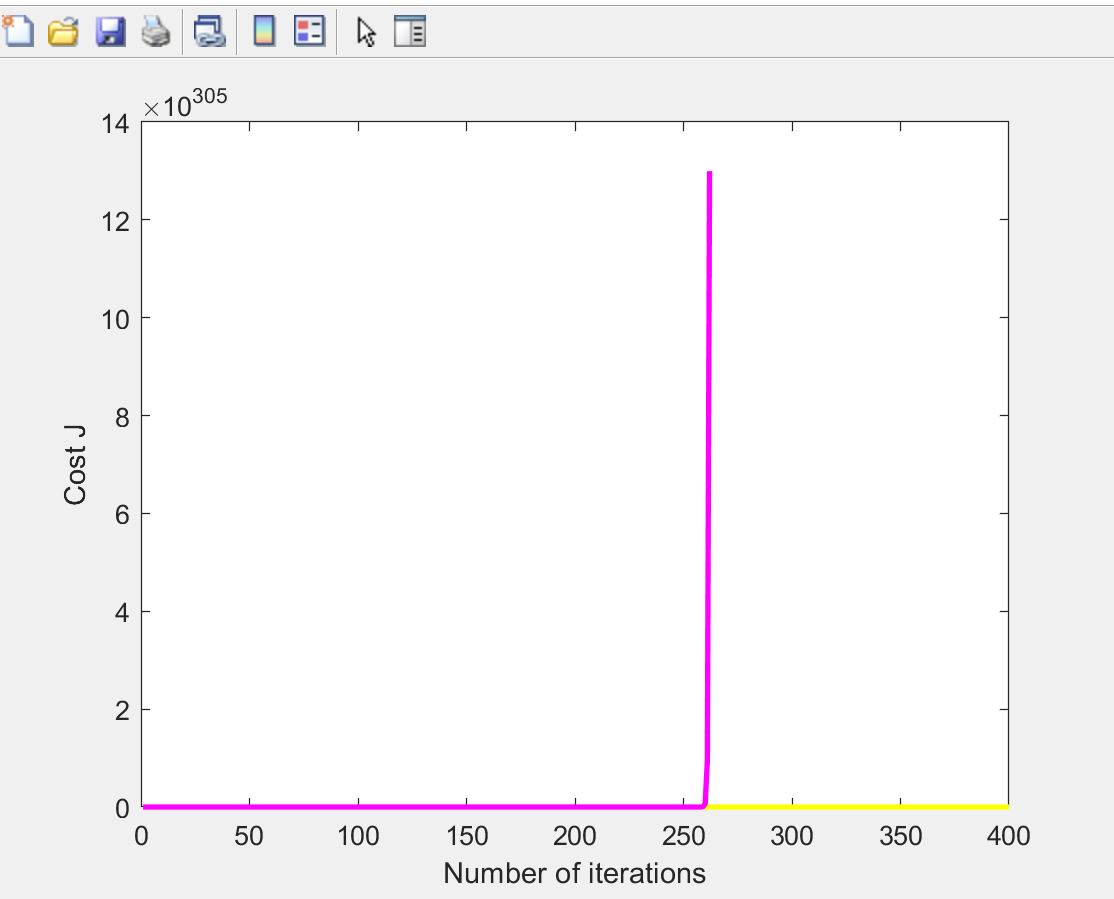
此时过大的学习率就会导致J函数发散diverge了
代码如下:
alpha1 = 0.01; |
以下是第二次作业
logistic regression 逻辑回归
给定的训练数据集包含两个feature, 和一个分类结果. 先对训练数据集进行可视化
pos = find(y==1); neg = find(y == 0); % 找到两种分类结果对应的索引 |
注意这里的作图: 横纵坐标都是X自变量, 真假(01)值是由点的样式来表示的.
计算J函数和梯度. 未正则化版
对于逻辑回归和sigmoid函数, 我们找到的theta参数同之前一样, 需要使得J函数达到最小值. 之后我们使用theta做一个乘法, 然后放进sigmoid函数, 根据sigmoid函数值0.5分界的特性做出预测.
J = 1/m*(-y'*log(sigmoid(X*theta)) - (1-y)'*log(1-sigmoid(X*theta))); |
根据sigmoid函数特性, 我们可以利用round()函数四舍五入实现
predict = round(sigmoid(X * theta)); |
对于nonlinear的分类, 可以增加自变量X的次方来解决, 即增加次数, 拟合出高次曲线, 例如:
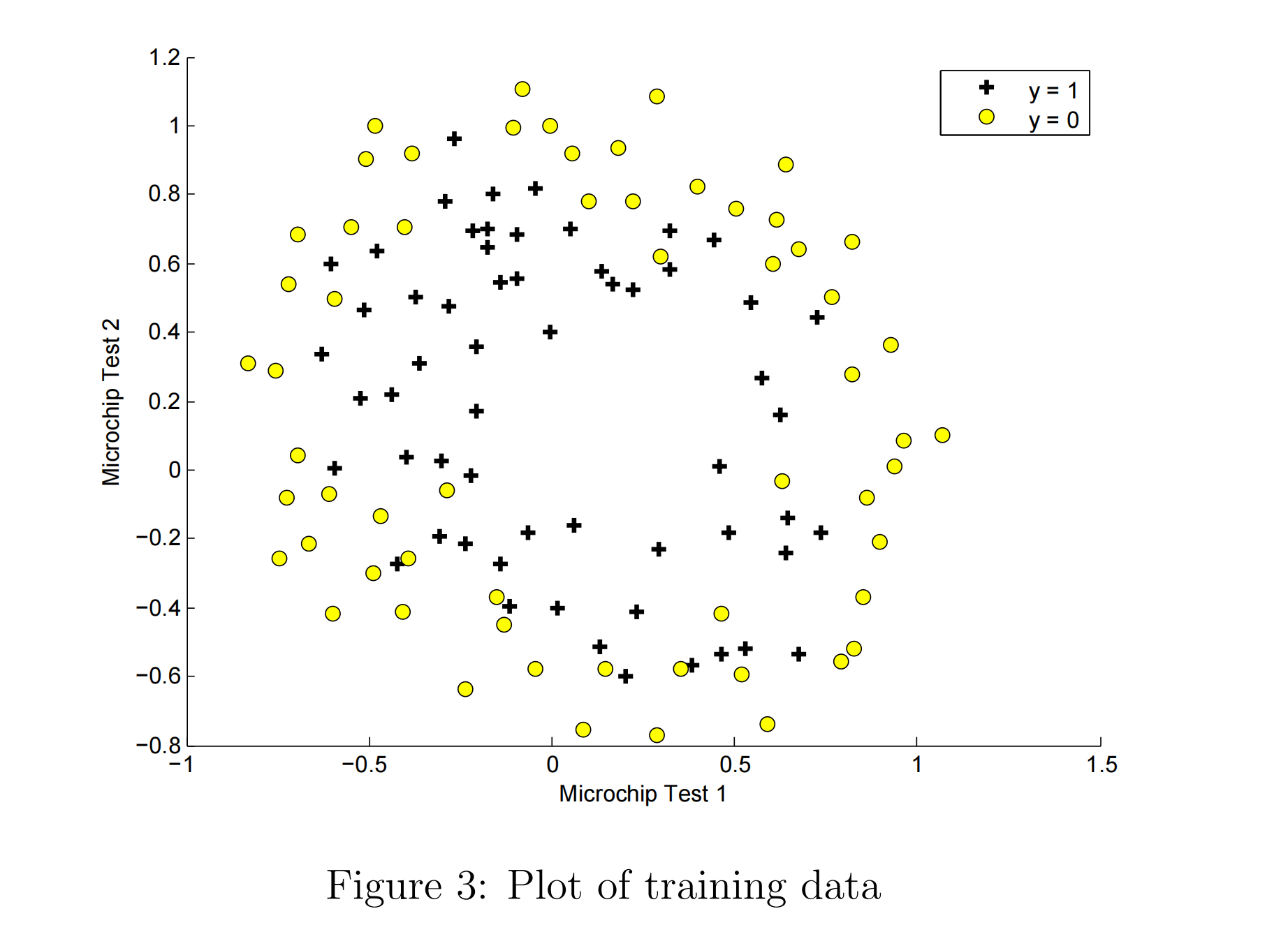
显然不能用直线来分类, 所以引入高次自变量多项式 polynomial
% 输入两个变量X1和X2, 进行他们两个的组合. 从0次到6次 |
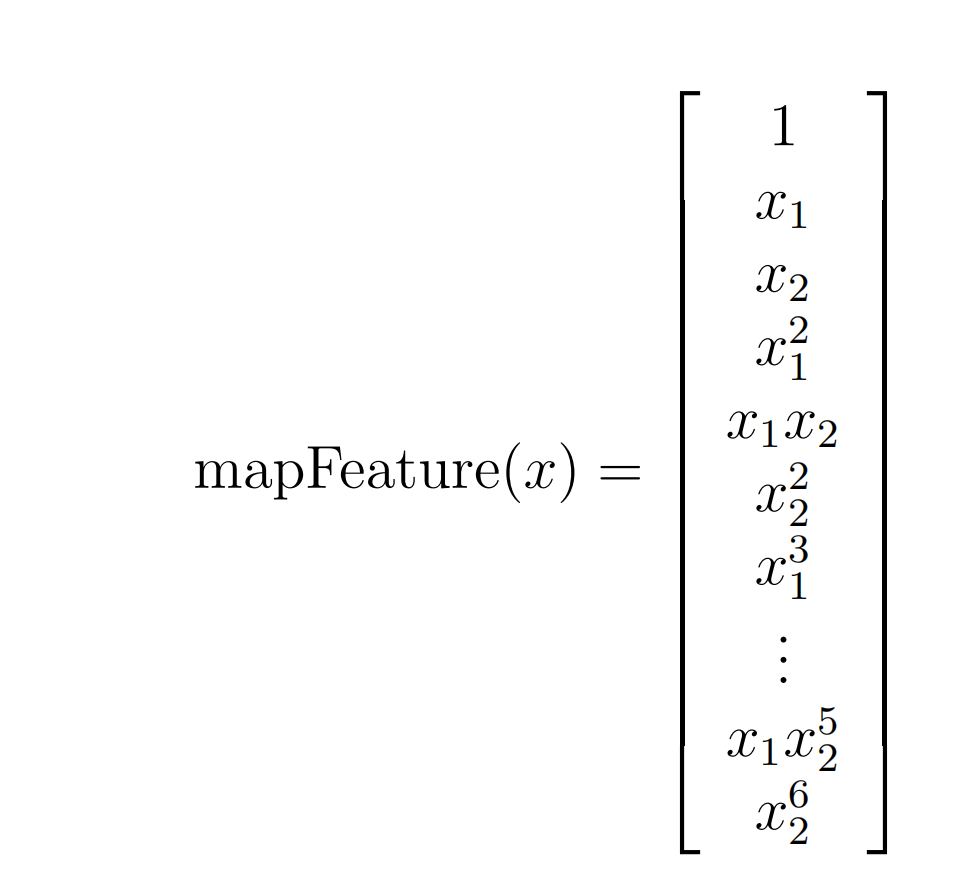
利用之前计算的J和梯度公式, 加以修改. 别忘了去除theta(1)
[J, grad] = costFunction(theta, X, y); |